Additional links:
- Original class material
<< Previous lecture | Next lecture >>
todo clean
Regression in Machine Learning
 Regression in a group of supervised learning techniques, alternative to classification. In classification, given a datapoint , the task was to learn a model such that represents one of the possible classes in which lies. On the other side, a Machine Learning problem is a Regression when the target variable is a continuous variable, and the task is to approximately interpolate between the values, with the intent of being able to predict new outcome of when a new is given as input.
Regression in a group of supervised learning techniques, alternative to classification. In classification, given a datapoint , the task was to learn a model such that represents one of the possible classes in which lies. On the other side, a Machine Learning problem is a Regression when the target variable is a continuous variable, and the task is to approximately interpolate between the values, with the intent of being able to predict new outcome of when a new is given as input.
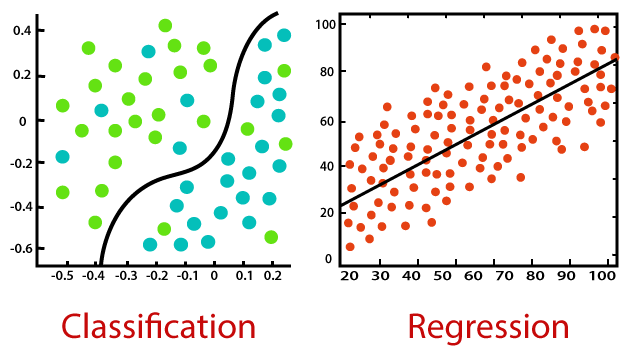 A part from that, the computation procedure to define a regression model is similar to the procedure required for a classification model. Indeed, let be a parametric function of , parameterized by . Given a dataset
A part from that, the computation procedure to define a regression model is similar to the procedure required for a classification model. Indeed, let be a parametric function of , parameterized by . Given a dataset
the task is to train the model such that for any . Clearly, this is done by solving the optimization problem
where the specific form of the loss function will be given in the next post. When , is called multivariate regression model, while if , is an univariate regression model. For simplicity, from now on we will work with univariate regression models, where for any , and consequently .
Linear Regression
The simplest regression model we can think of is the Linear Regression Model, defined as
where and . When is optimized, it defines a straight line approximating the data. Clearly, the resulting model will be correct if and only if the real function generating the data is linear. Unfortunately, even in situations where can be considered linear, the collected data is always corrupted by noise, which consequently breaks the linearity.
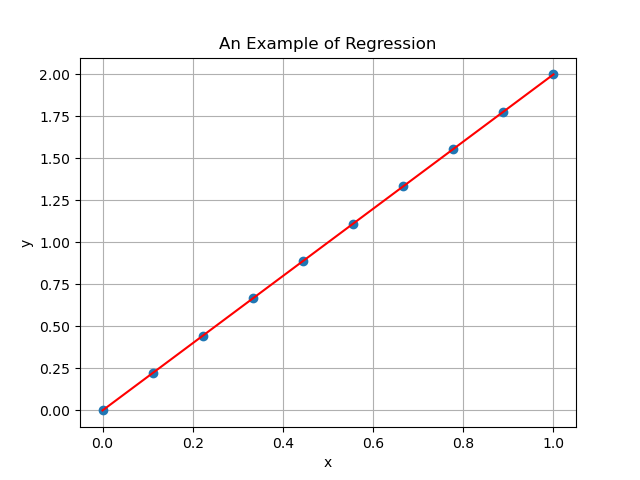
Consider for example a situation where is the model generating the data. The noiseless data , together with the line generated by the prediction model , in that situation will look like that
Unfortunately, since the data is always corrupted by noise, the collected data will be more like
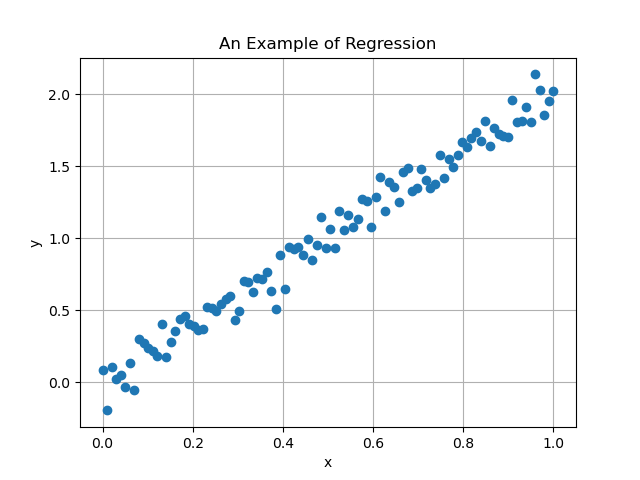
In this scenario, if as in the assumption above, then we hope to find parameters such that the resulting line will be close to the original one (first figure), someway ignoring the noise present in the data. Luckily, at least when the noise is Gaussian distributed, it usually does the job. Indeed the resulting linear regression model from the image above is
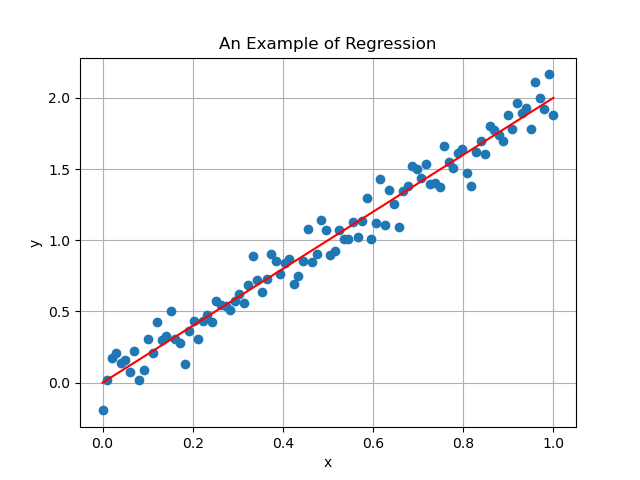 which is almost equal to the real line from the first image.
which is almost equal to the real line from the first image.
Polynomial Regression
In most of real life scenario, the linear regression model is too rigid to correctly approximate the data. Indeed, suppose to collect a dataset like
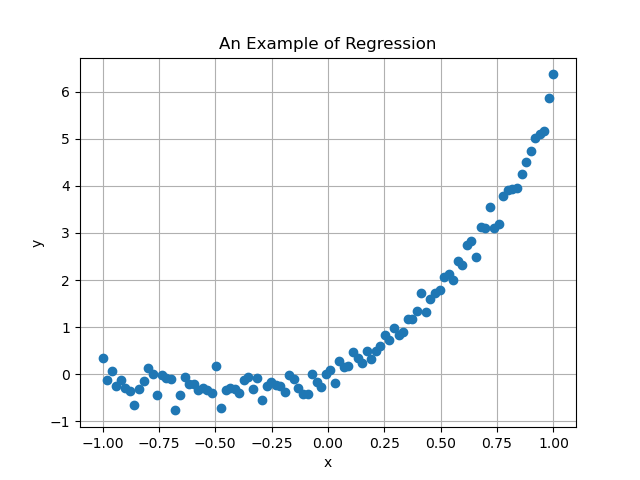 where it is clear that no straight line is able to correctly approximate it. Indeed, if we try to approximate it with a linear regression model, we obtain
where it is clear that no straight line is able to correctly approximate it. Indeed, if we try to approximate it with a linear regression model, we obtain
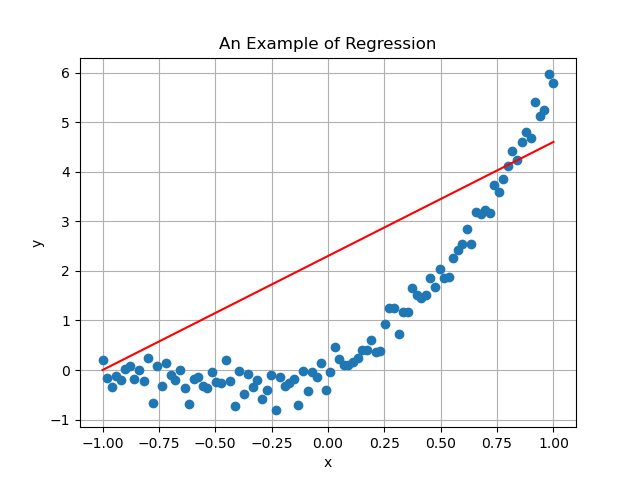 When this is the case, it is required to define a more flexible model.
When this is the case, it is required to define a more flexible model.
Given a number , define the regression model
where the functions are called feature vectors. Note that, for and , , we recover the linear regression model . For different values of and different feature vectors , we get different regression model.
Note that, if and , then
which implies that is a linear function in , for any choice of .
A classical choice for the feature vector, is . In this way, for a given , represents the vector of the first monomial in , i.e.
and is a -th degree polynomial. For this reason, is called polynomial regression model for this choice of . To show the improvement of a polynomial regression model against a linear model, this is the resulting model when we use a polynomial regression model of degree 3 on the data above:
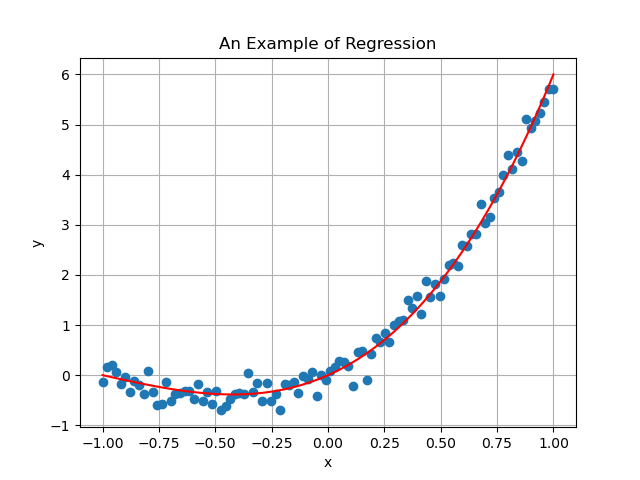 To understand how to train the parameters of a linear / polynomial regression model, we have to move to the next post.
To understand how to train the parameters of a linear / polynomial regression model, we have to move to the next post.