Additional links:
- Original class material
<< Previous lecture | Next lecture >>
todo clean
Introduction to Optimization
Consider a general continuous function . Given a set of admissible solutions , an optimization problem is a problem of the form
If , we say that the optimization is unconstrained. If , the problem is constrained. In this first part, we will always assume , i.e. the unconstrained setup.
Convexity
A common assumption in optimization is the convexity. By definition, a function is convex if
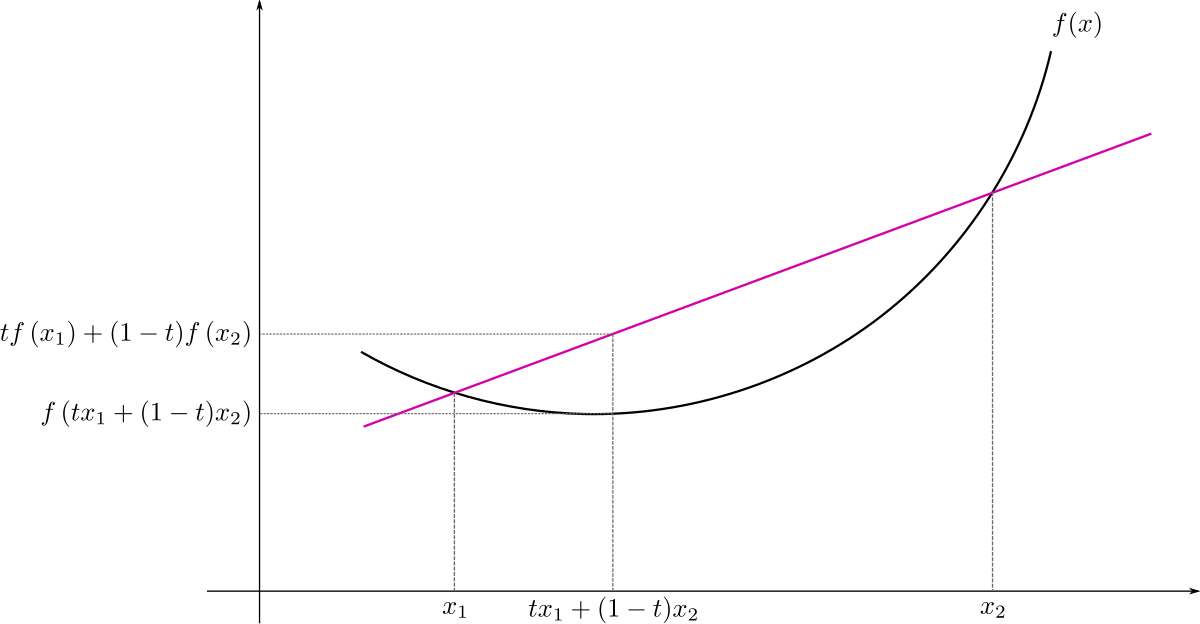
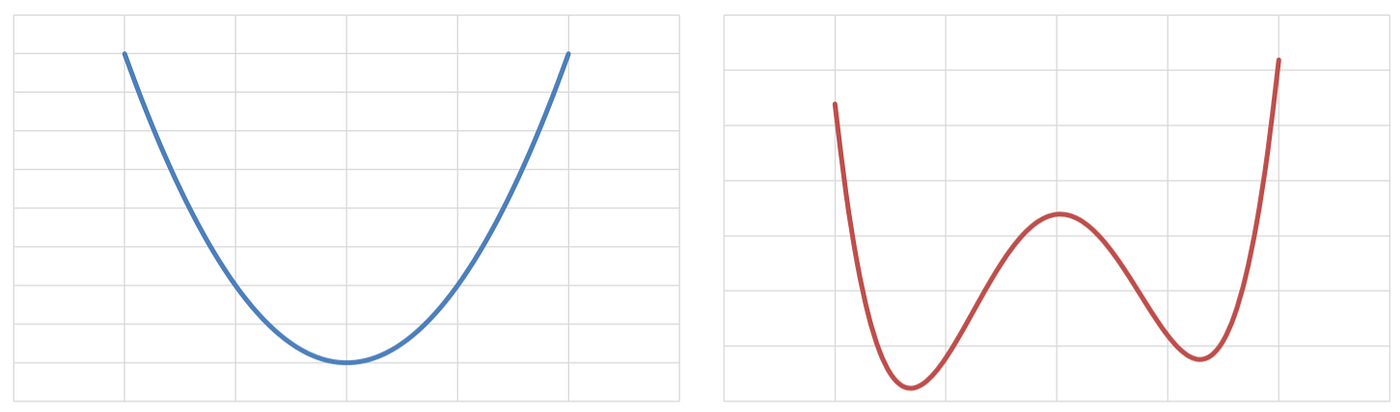
The importance of convex functions in optimization is that if is convex, than every minimum point of is a global minimum and the set of global minima is connected (the -dimensional extension of the concept of interval). On the other side, if a function is non-convex (NOTE: the opposite of convex is not concave), then there can be multiple distinct minimum points, some of which are local minimum while others are global minimum. Since in ML applications we want to find global minima, and discriminating between local and global minima of a function is an NP-hard problem, having convexity is a good thing.
First-order conditions
Most of the algorithms to find the minimum points of a given function are based on the following property:
First-order sufficient condition: If is a continuously differentiable function and is a minimum point of , then .
Moreover, it holds
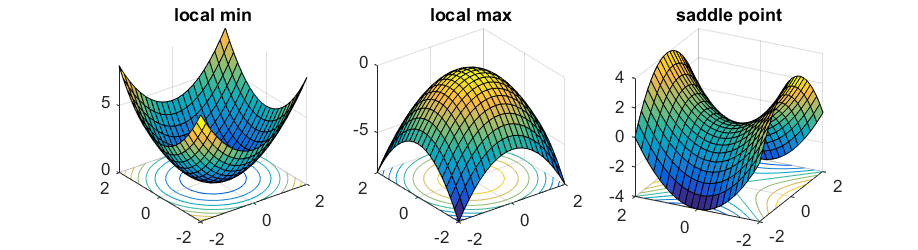
First-order necessary condition: If is a continuously differentiable function and for , then is either a (local) minimum, a (local) maximum or a saddle point of .
Consequently, we want to find a point such that . Those points are called stationary points of .
Gradient descent (GD)
The most common algorithm to solve optimization problems is the so-called Gradient Descent (GD). It is an iterative algorithm, i.e. an algorithm that iteratively updates the estimate of the solution, converging to the correct solution after infinite steps, such that, at each iteration, the successive estimate is computed by moving in the direction of maximum decreasing of : . Specifically,
where the initial iterate, , is given as input and the step-size (equivalently, learning rate) controls the decay rapidity of for any .
Choice the initial iterate
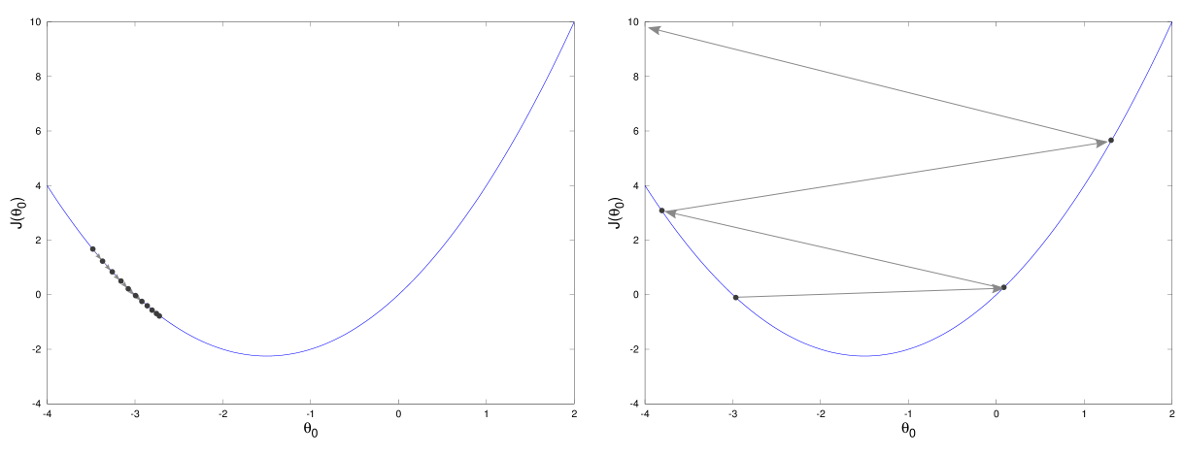
The Gradient Descent (GD) algorithm, always require the user to input an initial iterate . Theoretically, since GD has a global convergence proprerty, for any it will always converge to a stationary point of , i.e. to a point such that .
If is convex, then every stationary point is a (global) minimum of , implying that the choice of is not really important, and we can always use . On the other side, when is not convex, we have to choose such that it is as close as possible to the right stationary point, to increase the chances of getting to that. If an estimate of the correct minimum point is not available, we will just consider to get to a general local minima.
Step Size
Choosing the step size is the hardest component of gradient descent algorithm. Indeed, if is too small, there is a chance we never get to the minimum, getting closer and closer without reaching it. Moreover, we can easily get stuck on local minima when the objective function is non convex. On the contrary, if is too large, there is a chance we get stuck, bouncing back and forth around the minima.
Backtracking
Choosing the right step-size at each iteration is non-trivial. Indeed, convergence of Gradient Descent methods is only guaranteed if the step-size satisfies, for any , some conditions known as Wolfe Conditions:
- Sufficient decrease: ;
- Curvature condition: ; with .
Luckily, those conditions are automatically satisfied if is chosen by the backtracking algorithm. The idea of this algorithm is to start from an initial guess for , and then reducing it as with until the sufficient decrease condition is satisfied. A Python implementation for the backtracking algorithm can be found in the following.
import numpy as np
def backtracking(f, grad_f, x):
"""
This function is a simple implementation of the backtracking algorithm for
the GD (Gradient Descent) method.
f: function. The function that we want to optimize.
grad_f: function. The gradient of f(x).
x: ndarray. The actual iterate x_k.
"""
alpha = 1
c = 0.8
tau = 0.25
while f(x - alpha * grad_f(x)) > f(x) - c * alpha * np.linalg.norm(grad_f(x), 2) ** 2:
alpha = tau * alpha
if alpha < 1e-3:
break
return alphaStopping Criteria
The gradient descent is an iterative algorithm, meaning that it iteratively generates new estimates of the minima, starting from . Theoretically, after infinite iterations, we converge to the solution of the optimization problem but, since we cannot run infinite iterations, we have to find a way to tell the algorithm when its time to stop. A convergence condition for an iterative algorithm is called stopping criteria.
Remember that gradient descent aim to find stationary point. Consequently, it would make sense to use the norm of the gradient as a stopping criteria. In particular, it is common to check if the norm of the gradient on the actual iterate is below a certain tollerance and, if so, we stop the iterations. In particular
Stopping criteria 1: Given a tollerance , for any iterate , check whether or not . If so, stop the iterations.
Unfortunately, this condition alone is not sufficient. Indeed, if the function is almost flat around its minimum, then will be small even if will be far from the true minimum.
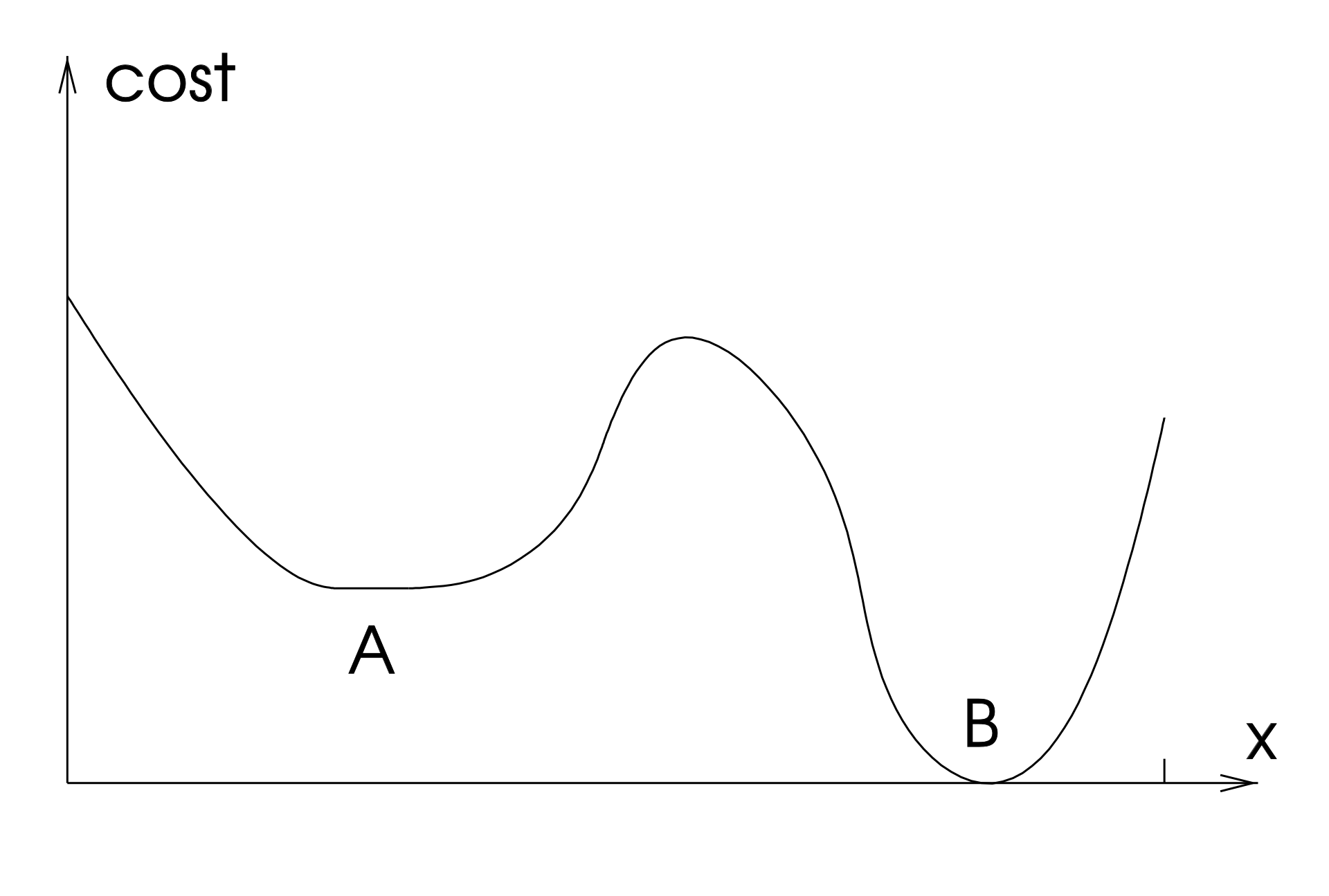 Consequently, its required to add another stopping criteria.
Consequently, its required to add another stopping criteria.
Stopping criteria 2: Given a tollerance , for any iterate , check whether or not . If so, stop the iterations.