Additional links:
- Original class material
<< Previous lecture |
todo clean
Binary Classification
Assume we are working in a binary classification setup, i.e. where the number of classes . In this case, we can always represent the two classes as and .
Consequently, we can develop a classification algorithm by defining a model such that and interpret the outcome of as the probability that . Thus, if , then our model predict that there are zero chances of being classified as , meaning that should be a 0. If , then will be classified as 1, while if then the model is not able to correctly identify the class of , since the chances of being are 50%.
An interesting feature of is that it turns a discontinuous task (i.e. mapping a real vector to a discrete value ) into a continuous problem. The discreteness of the outcome is then recovered by mapping to 1 if , to 0 is . In formula, a datapoint will be classified as:
What is logistic regression?
Logistic Regression is a widely known, beginner-level, binary classification algorithm based on the probabilistic approach framework. The idea is simple: consider a dataset
and consider a linear function with unknown parameters over each of the datapoints . This operation can be rewritten as . Consequently, define the extended dataset , computed adding a 1 to each datapoint, i.e.
where
Then, for any , consider the model
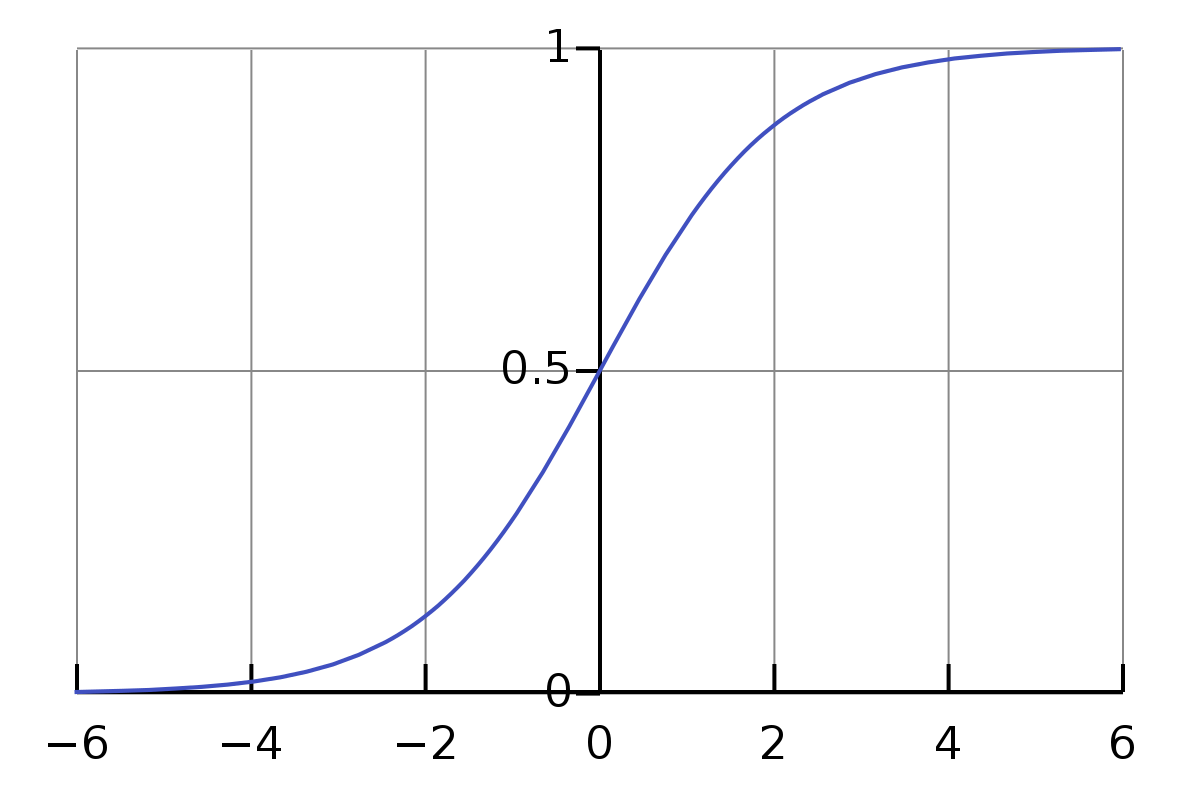
where is the weight vector, and is the sigmoid function, defined as
whose scope is to squeeze the real axis to the domain (to get the probabilistic interpretation).
 Since the output of is continuous, it is natural to select, as loss function, the Mean Squared Error, as defined previously. Indeed, the loss function becomes
Since the output of is continuous, it is natural to select, as loss function, the Mean Squared Error, as defined previously. Indeed, the loss function becomes
and the training procedure is
which can be done by Gradient Descent (or, alternatively, Stochastic Gradient Descent), whose iteration is
for which we are required to compute
Since
then
since by \eqref{eq:model_definition}, then the chain rule implies that
An interesting feature of is that , impliying that
and
which finally leads to
which converges to the solution of \eqref{eq:training_procedure} for .
Python Implementation
Before we can start with the implementation notes, observe that we can do some operations to simplify the coding and the efficiency of it. Indeed, given the dataset , define
and
Consequently, we can re-write \eqref{eq:loss_function} as
and, by following the same procedure we did before, we get to the compact form of \eqref{eq:final_GD_iteration}:
where is the element-wise multiplication. To check that the shapes in Equation \eqref{eq:final_GD_iteration_compact} are correct, let’s do a sanity check:
- has shape , where in this case;
- has shape by definition, then has shape ;
- does not affect the shape of the input, then has shape ;
- Both and have shape , then has shape .
- Consequently, has shape because of the element-wise multiplication;
- Finally, has shape , which is the same shape of , then the computation is correct.
Equation \eqref{eq:final_GD_iteration_compact} is what we are going to implement.
Data Loading and Pre-processing
We are going to test logistic regression on a simulated dataset from the library sklearn. Loading it into memory is very easy:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
# Load data
X, Y = make_classification(n_samples=500, n_features=2, n_redundant=0, n_informative=1,
n_clusters_per_class=1)
X = X.T # To make it d x N
# Check the shape
print(f"Shape of X: {X.shape}")
print(f"Shape of Y: {Y.shape}")
# Memorize the shape
d, N = X.shape
# Add dimension on Y
Y = Y.reshape((N, 1))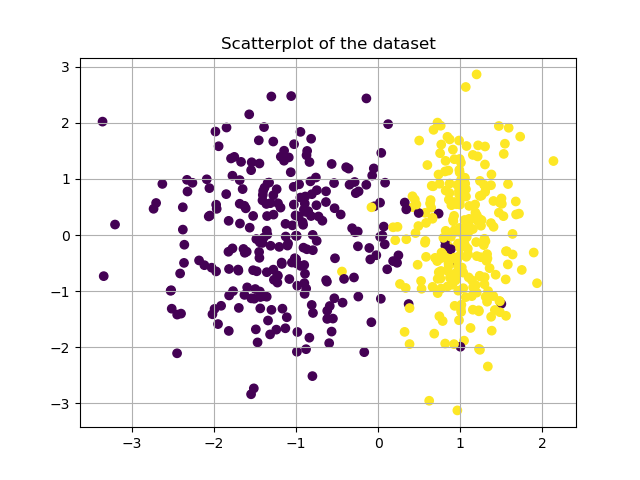
To conclude the data loading step, we need to build the dataset from above. This can be simply done by
# Create Xhat
Xhat = np.concatenate((np.ones((N,1)), X), axis=0)Build the model
Remember that
thus, we need to define the sigmoid function .
# Define sigmoid
def sigmoid(x):
...The results of the application of on is not hard to compute.
# Compute the value of f
def f(w, xhat):
...Training
To perform the training, it is sufficient to implement the loss function and its gradient, which can be simply done by following the formulas above
# Value of the loss
def ell(w, X, Y):
...
# Value of the gradient
def grad_ell(w, X, Y):
...After training, the prediction over new data can be simply done by
def predict(w, X, treshold=0.5):
...Results
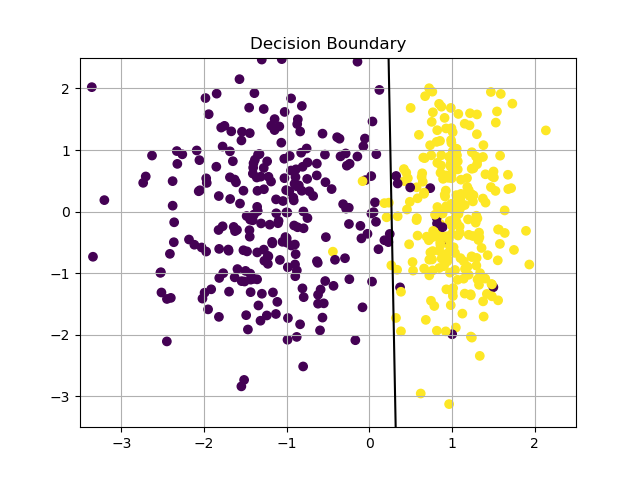
The result is a -ple of weights such that . When , the term inside of the sigmoid is the equation of a straight line , which can be re-written in explicit form as
which is the decision boundary for the classification problem. Here it is a plot of the resulting classifier.
Extension to case
If the number of classes is bigger than 2, logistic regression can still be applied, with slight modifications. In particular, let be the number of classes . Then, we define to be a matrix,
where is a vector of probabilities (i.e. for any and ) summing to one, i.e.
Intuitively, represents the probability the is a member of the class . To enforce the condition \eqref{eq:summing_to_one}, it is mandatory to set
where is defined as
such that
Note that, in the multi-class scenario, the weights are matrices, so that is an matrix.